



Le projet ·W·I·L·D· construit progressivement une bibliothèque informatique OpenSource pour traiter les données environnementales. Les développements peuvent être imbriqués dans des scénarios simples pour venir appuyer des projets métiers : traitements en ligne, recoupements dynamiques, processus chaînés, analyses et statistiques...
Une interface originale, sous forme de réseau social, permet aux utilisateurs de mobiliser ces fonctions.
 |
·W·I·L·D· Wrappers & Interroperability for Lazy Developpers De nombreux acteurs participent à ce projet : contributeurs de code, fournisseurs de données, administrateurs de données, participants à des projets de recherche, organismes de formation... Contact : Alexandre Liccardi (AFB/DAPP) |
Une boîte à outil pour le traitement des données environnementales
·W·I·L·D· propose un ensemble d'outils pour les ingénieurs en charge du traitement des données environnementales : en premier lieu, le projet vise à développer une boîte à outils informatique, sous forme d'objets de programmation (POO) et de méthodes associées. Ces objets doivent être très facilement compréhensibles, mobilisables sans connaissance poussée des systèmes sous-jacents et fiables : ils reposent sur des bibliothèques OpenSource éprouvés. Ces fonctionnalités, agencées sous forme de briques, sont accessibles par des portails qui permettent aux ingénieurs métiers de composer des cas d'utilsation (scénarios) poussés : ·W·I·L·D· devient alors une plateforme de traitement de données, poussée par une interface web.
Enfin, ces mêmes briques sont utilisées dans les projets d'ingénierie informatique en appui aux métiers, permettant de mutualiser les développements : capter et utiliser des flux webs, vérifier des schémas de données, réaliser des recoupements géographiques sont déjà, par exemple, implémentés.
Objectif de mutualisation : des problématiques distinctes, des fonctionnalités proches
Le constat à l'origine du projet est la redondance de certaines fonctionnalités dans les traitements informatiques des données, de manière transversale à différents domaines d'analyse environnementale. L'ingénieur de données réalise par exemple, en amont de chaque mission, des conversions de formats et des tests de vérification (tests référentiels, tests de complétude, tests de qualité de l'information...). De même, il est souvent appelé à utiliser des échelles similaires (échelle administrative, échelle des zonages hydrographiques BD CARTHAGE par exemple) pour agréger des objets fournis sous forme de géométries.
Dans ces opérations, une part de l'effort est commun (ici, la comparaison et/ou le calcul), une part est spécifique à l'analyse (ici, les séries d'entrée). Identifier la part mutualisable des traitements, fournir cette part mutualisée sous forme de code informatique et prévoir une configuration simple et adaptée aux métiers est donc le premier objectif de ·W·I·L·D·.
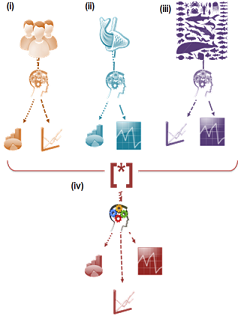 |
Mutualiser les fonctionnalités des projets requiert un certain recul. Dans cet exemple fictif, le projet (i) gère du personnel. Il produit des histogrammes et des graphiques en courbes. Le projet (ii) suit les pêcheries et est spécialisé dans les analyses temporelles et les histogrammes, le troisième projet (iii) s'intéresse à la biodiversité et n'est pas doté de fonctionnalités histogrammes. L'objectif de mutualisation fonctionnelle est d'identifier les éléments similaires et/ou portables d'un projet à l'autre, pour produire un modèle (iv) capable de fournir les trois types de représentations demandées. L'utilisateur devra in fine spécifier des paramètres d'adaptation à sa thématique (choix des variables, sémiologie, types de règles d'agrégation...). |
Objectif opérationnel: une cible très large dans les SI environnementaux
Le champs des analyses environnementales est très vaste, et le besoin important : les données recueillies par l'Agence Française de la Biodiversité et plus largement par le SIE portent sur la physico-chimie, l'hydrologie, l'hydromorphologie, les débits d'eau, les inventaires biologiques, la bathymétrie, l'économie de l'eau, la performance des services de traitements et d'eau potable (...). La consultation du portail EauFrance et du catalogue data.eaufrance donnent une idée du spectre concerné.
·W·I·L·D· est un projet OpenSource ouvert à tous ses contributeurs et plus largement à tous les ingénieurs de données ; les fonctionnalités produites doivent donc être à la fois spécifiques et adaptées aux besoins métiers, mais suffisamment ouvertes pour intégrer de nouvelles problématiques. La bibliothèque est modulable, facilement paramétrable et mobilisable par des appels simples. L'approche OpenSource doit inciter les développeurs et les ingénieurs à intégrer leurs propres fonctionnalités dans le code source.
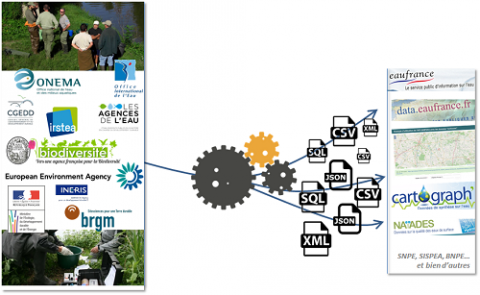
Une grande diversité de projets, une hétérogénéité importante des données d'entrée, des acteurs et des besoins différents : les ingénieurs doivent utiliser de nombreux formats différents, mobiliser des traitements géographiques, chaînés, filtrés, massifs, croisés (...) pour alimenter les portails d'accès aux données opendata. Afin de garantir la qualité des informations et de permettre leur réutilisation, il est nécessaire d'administrer des référentiels de données (comme ceux produits par le SANDRE) et des traitements documentés, ouverts et reproductibles : un "référentiel de fonctions" accessibles à l'utilisateur.
La plateforme de traitement de données
La plateforme de traitement de données est le système qui mobilise la bibliothèque ·W·I·L·D· dynamiquement, à partir de fichiers de composition d'objets très simples. Cette plateforme dispose d'une interface qui permet aux utilisateurs :
- de spécifier et de configurer les travaux à lancer, depuis un formulaire généré dynamiquement depuis la documentation ;
- de lancer les travaux, de suivre l'avancement, de récupérer les résultats ;
- de stocker les réalisations, d'échanger les produits des travaux ;
- d'échanger entre utilisateurs.
 |
La plateforme WILD utilise les développements comme un "moteur de traitement". Une base de données permet de stocker les informations nécessaires à l'exécution et à l'archivage des tests, ainsi que quelques référentiels pré-traités. Outre l'aspect traitements, l'interface constitue un véritable environnement de travail rappelant les réseaux sociaux. Les éléments communiquent entre eux par API.
|
Un modèle riche et extensible
La partie "traitements" est propulsée par la bibliothèque, contenue dans des jobs Quartz. Cette partie forme un service qui gère les priorités de traitment et les files d'attentes.
Les fonctionnalités de la plateforme sous directement dictées par le modèle applicatif de la bibliothèque, qui contient des objets simple (par exemple, le fichier SIG), des objets plus spécifiques (exemple du fichier SIG SHP), enfin des objets héritant de toutres les fonctionnalités des précédents (notion d'héritage), mais déclinant des fonctions très spécifiques à un projet métier (par exemple, le fichier SHP propre à l'opération de Rapportage des masses d'eau à la Commission Européenne).
 |
Le package REAL, représenté ici (cliquer pour agrandir), permet de charger les données depuis des fichiers ou des services vers les fonctionnalités de traitement. Pour les ingénieurs, il correspond à des objets informatiques bien connu et est facilement mobilisable. ·W·I·L·D· peut aussi être perçue comme une "surcouche" des bibliothèque OpenSource les plus souvent mobilisées. L'ingénieur n'a pas à connaître le détail des bibliothèques sous-jacentes : il s'adresse à tous les objets de la même manière. |

Le développement de la bibliothèque ·W·I·L·D· utilise des bibliothèques OpenSource pré-existantes, et cherche à minimiser la quantité de code produite. Le code source est sous licence GPLv3.
Un outil social, personnalisé et intégré
L'utilisation du service de traitement des données n'est possible que si l'interface est ergonomique. L'interface identifie l'utilisateur et lui donne accès à un dossier de fichier, contenant ses données et ses archives de traitement.
Les premières expériences ont conduit à mettre en place un système de billet et de publication des résultats, afin de construire des échanges autour de l'utilisation des scénarios proposés, de la proposition de nouveaux scénarios, mais surtout autour des produits de traitements. Les utilisateurs peuvent plus simplement commuiniquer entre eux et s'échanger des jeux de données. Des fils de discussion, classés par tags ou mots-clés, se construisent.
L'utilisateur a accès aux traitements (sous forme de scénarios) et aux référentiels (sous forme de séries de données), selon les droits qui lui sont attribués (depuis invité , puis participant, puis ingénieur, puis chef de projet et enfin administrateur).

Le développement de l'interface DICE utilise des architectures et des services OpenSource pré-existants. Le code source est sous licence GPLv3.
L'interopérabilité pour simplifier l'utilisation
Dans les "fonctionnalités mutualisables" des travaux des ingénieurs de données, l'appel successif de plusieurs services distants (le chaînage de services) est omniprésent. En effet, les systèmes sont aujourd'hui largement répartis et accessibles sous forme d'API. La modularité de la bibliothèque ·W·I·L·D· lui permet de capter des séries de données ou des résultats de traitements produits par d'autres machines (par exemple, les référentiels produits par le SANDRE, le séries de l'INSEE, les calculs du système d'évaluation de l'état écologique SEEE, l'accès au catalogue WISE) et de réagir en fonction du contenu des informations récupérées. Des logiques plus ou moins complexes peuvent être mises en oeuvre : une application consiste à simuler le comportement des ingénieurs métiers, lorsqu'ils parcourent le résultat d'un service ou une page web. L'opération est reproduite un grand nombre de fois pour produire des statistiques ou pour remplir des bases de donnes (scrapping par simulation de comportement utilisateur).
Les exemple fournis ci-après concernent ce type de traitements, chaque exemple est axé sur un projet métier particulier.
Première utilisation : le guichet Rapportages DCE
 |
Le guichet Rapportages DCE a été mis en place par l'ONEMA pour les établissements participant à la remontée des données d'état des eaux continentales superficielles à la Commission Européenne, de mars à décembre 2016 (voir le site Rapportages). Le guichet a pour mission de réaliser différents tests de conformité et de qualité des données, sur des fichiers XML chargés par les utilisateurs. Les utilisateurs récupèrent des rapports tabulaires et graphiques leur permettant d'identifier très rapidement les erreurs repérées, comme les masses d'eau ou les stations mal renseignées, les lignes exactes des erreurs et des indications de correction. Les fonctionnalités sociales de l'interface ont été mobilisées, car le nombre de tests réalisés par chaque utilisateur était important (parfois supérieur à 100 par jour, une centaine d'utilisateurs inscrits) et un retour nécessaire. |
 |
Les traitements réalisés peuvent être simples (contrôles de schémas, de formats), plus complexes (exécution d'algorithme produits par la Commission Europe, dont un contrôle de version est nécessaire), ou complexes (par exemple, comparaison à des sources de données référentielles externes). L'exemple ci-contre (cliquer pour lancer l'animation) montre qu'une fois le fichier transféré et le scénario lancé (étapes 1 à 3), les tests successifs réagissent selon le contenu du retour du flux (étapes 4 et 4.x): la Commission a-t-elle mis à jour ses traitements ? Les données sont-elles conformes aux référentiels en ligne, eux-mêmes susceptibles d'évoluer ? |
Deuxième utilisation : O-WS, "O" (Open, Eau) WebServices
 |
O-WS est un service de test des flux des données publiques relatives à l'eau. Ce n'est pas un outil de monitoring technique (les interruptions de service, les débits etc. sont fournis par l'hébergeur, même si O-WS produit des statistiques), mais une plateforme de simulation des comportements utilisateur. Les développements utilisent ·W·I·L·D· pour reproduire chaque heure, sur plus d'une dizaine de services, une série d'actions de recette prévue par les administrateurs de données. L'utilisateur dicte le comportement initial : interpréter les résultats est aisé pour lui. Une interface graphique dédiée axée reporting, en cours de développement, permettra la visualisation des indicateurs de cette expérience virtuelle, au cours du temps; |
|
|
Certains comportement simulés peuvent être complexes : utiliser les flux Agences de l'Eau pour récupérer les données physico-chimie, par exemple (cliquer pour lancer l'animation), implique de lancer 4 requêtes successives sur les serveurs Agences, puis deux requêtes en cascade vers les serveurs SANDRE pour vérifier la validité des données. L'essentiel des requêtes et des tests sont produits par les serveurs distants. Dans cet exemple, on récupère la liste de tous les sites d'observation (1 rouge), on en pioche 10 au hasard, on récupère la description de ces sites (2 rouge), on demande la liste des analyses disponibles (1 blanc) et on récupère une année sur un paramètre (2 blanc). Les vérifications sont produites en 3, à chaque retour (4) on décide de poursuivre l'opération. |

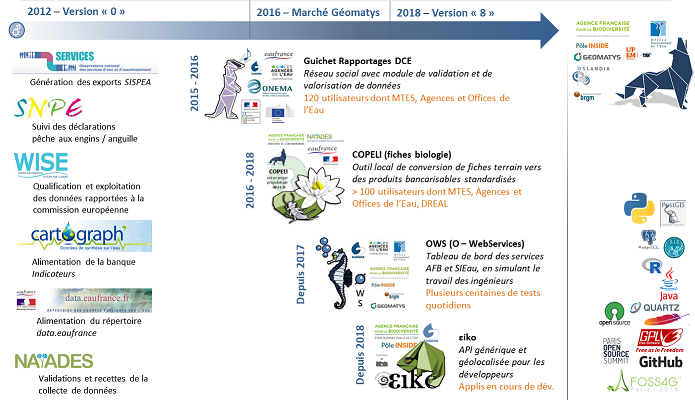
RoadMap et synthèse des cas d'utilisation en juillet 2018
Dernière mise à jour le 18.05.2020